# 데이터 준비
DDB를 사용하기 전에 가지고있는 데이터와 필요한 워크 플로를 이해하는 것이 중요합니다.
# 워크 플로는 무엇입니까?
워크 플로를 식별하려면 다음 단계를 수행 할 수 있습니다.
- 동적 필드를 식별하십시오
- 데이터의 흐름을 식별하십시오
- 매개 변수를 식별하십시오
- 적절한 자산 계층을 식별하십시오
- 매개 변수를 자산에 맵핑합니다
- 모든 입력의 소스를 식별하십시오
- 프로세스를 확장하기 위해 이전 단계를 반복하십시오
# 1. 동적 필드를 식별하십시오
먼저, 보고서에서 동적 필드, 각 프로젝트간에 변화하는 것들을 식별합니다. 계산에 사용하는 값, 보고서의 텍스트 필드 또는 전적으로 다른 것일 수 있습니다. 이 예에서 동적 필드는이 프로젝트와 관련된 값과 텍스트입니다. 문서의 다른 모든 텍스트는 정적입니다.
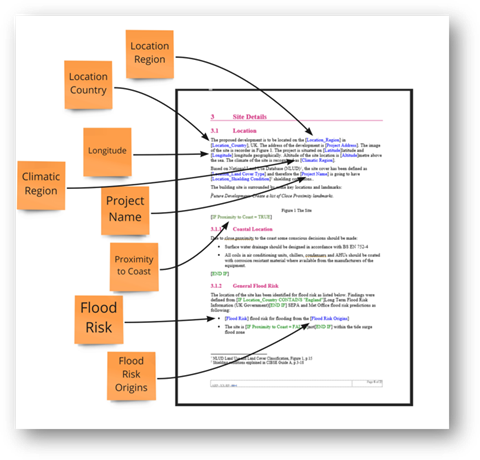
# 2. 데이터의 흐름을 식별하십시오
다음으로 워크 플로에서 데이터가 프로세스에서 프로세스로 이동하는 방법 과이 데이터를 이동하는 데 필요한 도구를 이해해야합니다.
이 예에서는 DDB를 데이터 허브로 사용하고 보고서 템플릿에 HOTDOCS를 사용하고 K2는 값으로 설계 보고서의 기계적 기초를 채 웁니다.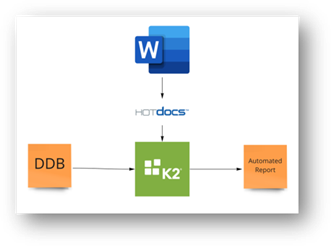
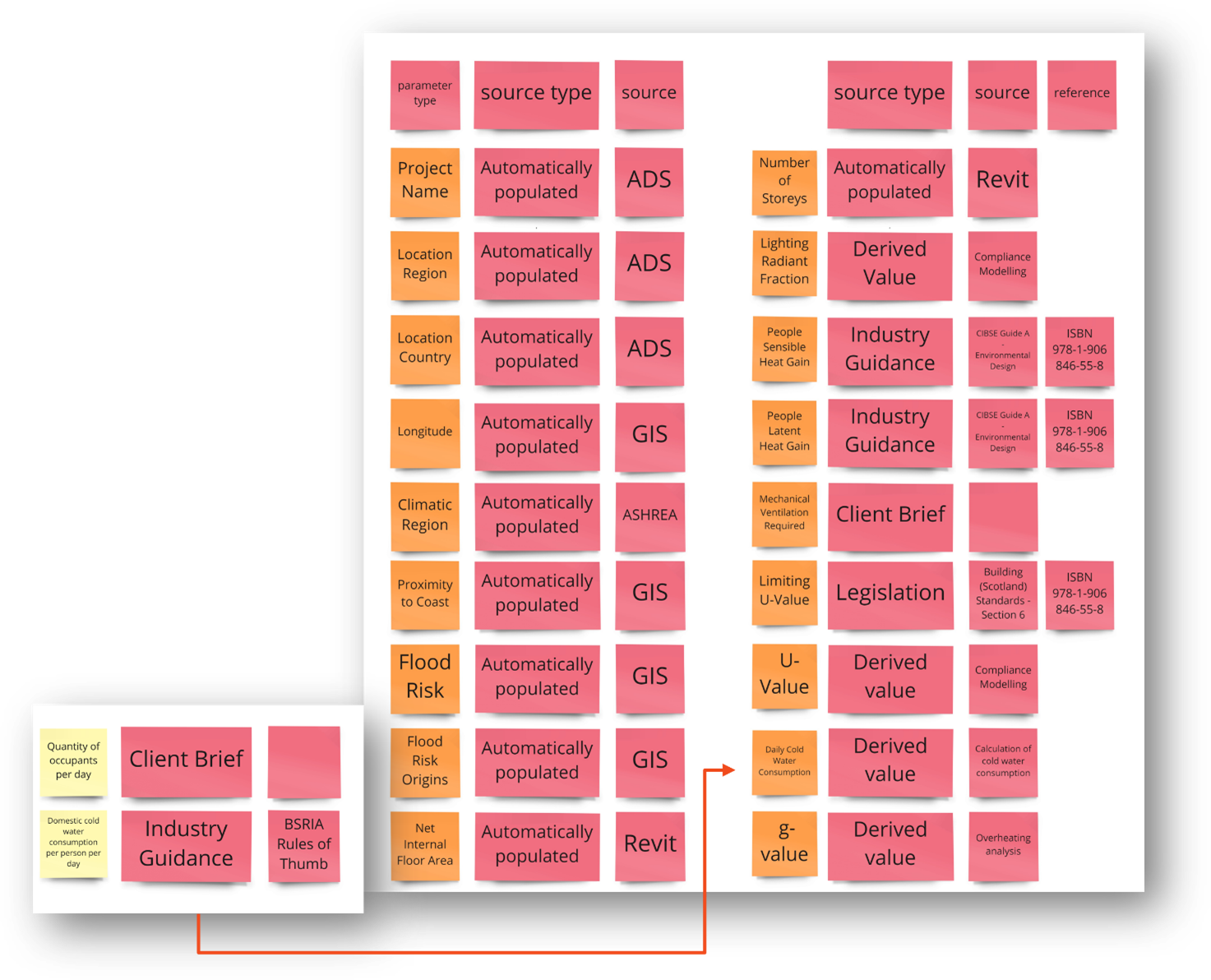
# 3. 매개 변수를 식별하십시오
정보의 흐름을 매핑 했으므로 매개 변수를 지정해야합니다. 정확히 각 필드에 들어가는 데이터,이 필드가 허용 할 데이터 유형 및 이와 관련된 단위 (있는 경우)를 기록해야합니다.

# 4. 적절한 자산 계층을 식별하십시오
우리는 어떤 물리적 인 것 - 어떤 자산과 관련된 매개 변수와 어떤 자산 계층이 우리의 사용 사례에 적합한 지 고려해야합니다. 이 예에서 우리는 건물 프로젝트를 진행하고 있으며 기존 계층은 사용 사례에 매우 효과적입니다. 계층 구조에 대한 혼란이 있거나 변경이 필요한 경우 DDB 온 보딩 팀에 문의하여 논의하십시오.
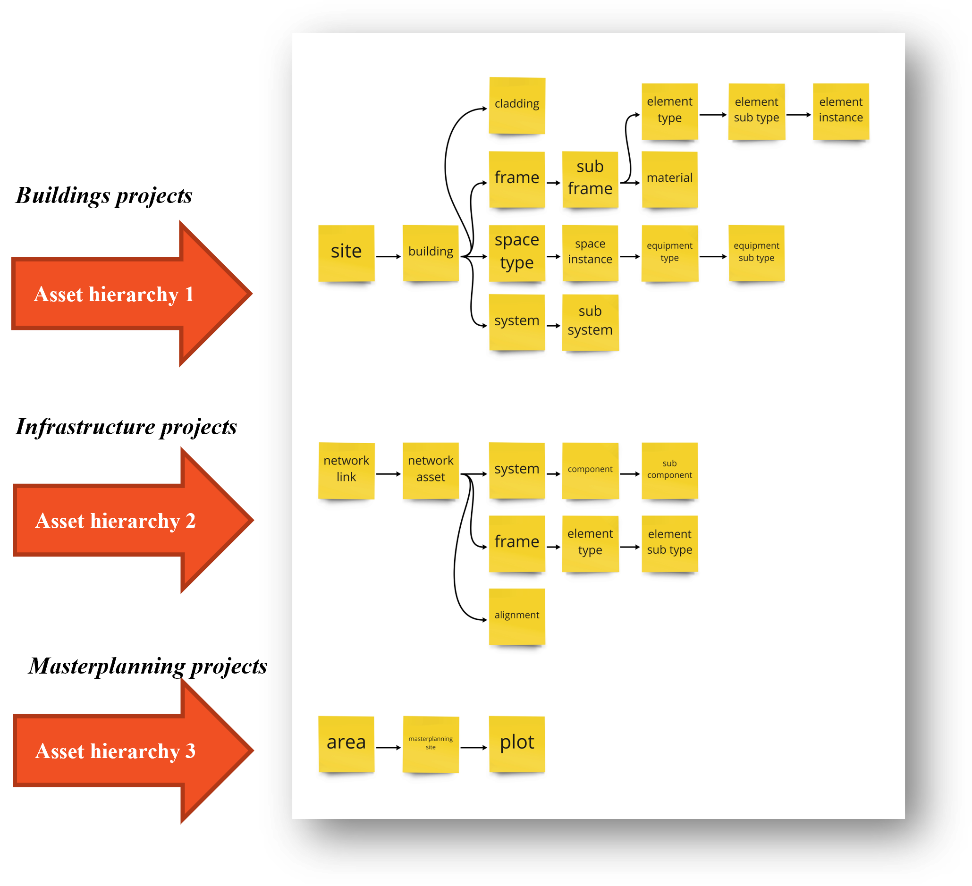
# 5. 매개 변수를 자산에 매핑합니다
우리가 선택한 자산 계층을 기억하기 위해, 우리는이 프로세스에 필요한 모든 매개 변수를 관련 자산에 매핑하고 부모-자식 관계의 흐름이 프로젝트에 적합하도록해야합니다. 그렇지 않으면 다른 자산 유형 및/또는 계층이 필요할 수 있습니다.
이 예에서 노란색 상자는 계층 구조의 자산 유형이고, 분홍색은 자산의 인스턴스이며, 오렌지는이 자산 인스턴스와 관련된 매개 변수입니다.
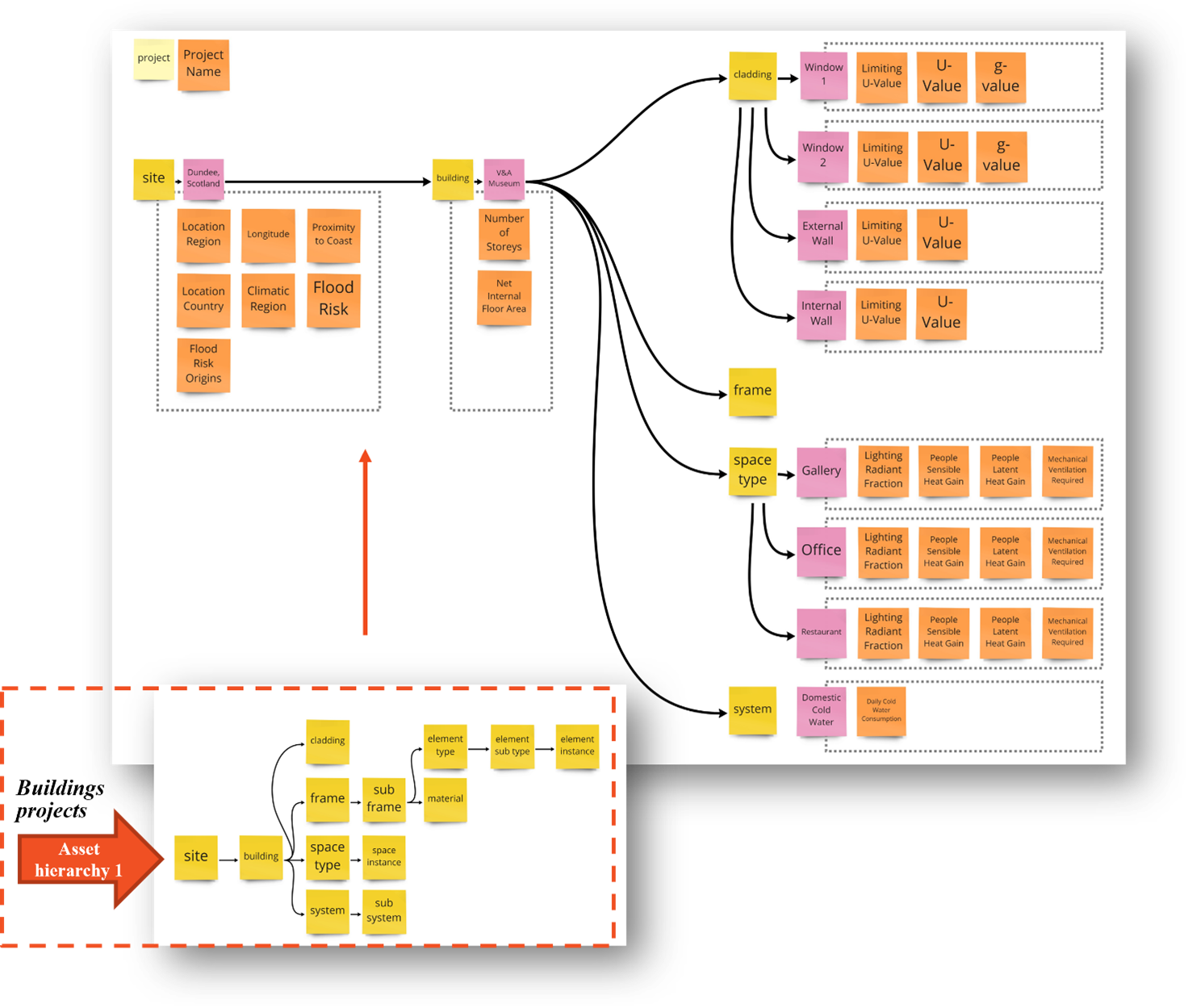
메모: DDB 팀은 현재 매개 변수 가용성을 관리하고 있습니다. 계층 구조의 다른 수준의 매개 변수가 현재 유발할 수있는 것과 관련하여 매개 변수 요청 양식 (opens new window) 또는 연락하십시오.
# 6. 모든 입력의 소스를 식별하십시오
이제 우리는 프로젝트 나 위치 사이에 변경 될 수있는 문서, 소프트웨어로 생성 된 경우 또는 다른 수단에 의해 도출 된 경우 모든 입력 값의 소스를 식별해야합니다. 출처에는 오리지널 정보 출처에 대한 날짜 및 링크가 포함되어야합니다.
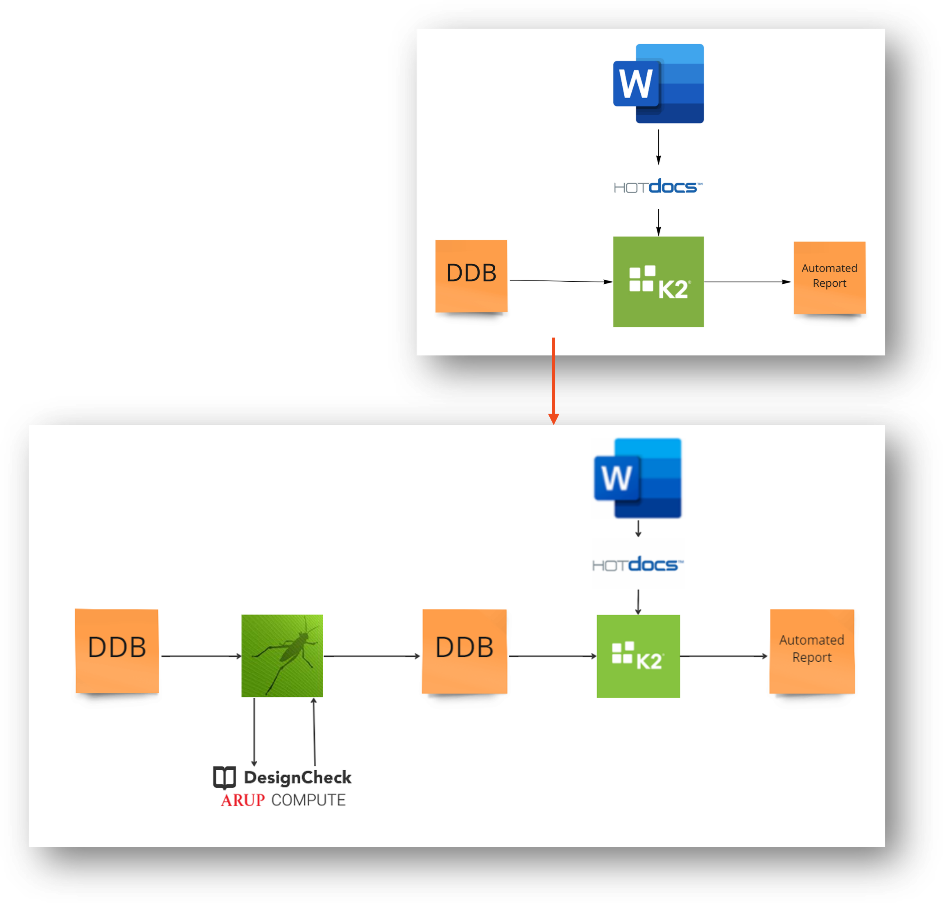
# 7. 프로세스를 확장하기 위해 이전 단계를 반복하십시오
입력 생성을 자동화하거나 출력 범위를 확장하기 위해 동일한 워크 플로우에 따라 프로세스를 계속 확장 할 수 있습니다.
이 예에서는 자동화 된보고 프로세스에 대한 입력을 Grasshopper의 통합을 사용하여 DDB에 계산하고 업로드 할 수 있습니다.
확인하십시오 데이터 업로드 도구 이것이 DDB를 신속하게 시작하는 데 도움이 될지 확인하십시오.