# 用語と定義の用語集
DDB プラットフォームとドキュメント全体で使用され、参照される基本的な概念がいくつかあります。
# 環境
DDB には、目的が異なる 3 つの異なる環境があります。
| 環境 | URL | 説明 | いつ使用するか |
|---|---|---|---|
| 発達 | dev.ddb.arup.com (opens new window) | 1 つ目は、主に開発チームが新しい機能をテストするために使用する DDB 開発サイトです。 このサーバーは警告なしに定期的に拭き取られているため、ライブプロジェクトデータをそこに保存しないでください。 DDB チームは、この環境に保存されているデータ損失について責任を負いません。 | データモデルを探索するときは、この環境を使用してください。 物事を壊しても大丈夫です。 |
| サンドボックス | sandbox.ddb.arup.com (opens new window) | 2 つ目は、初期の採用者やワークショップ参加者が機能をテストし、ユーザーインターフェイスに精通するために使用される DDB サンドボックスサイトです。 ここではデータがランダムに拭かれませんが、ライブプロジェクトデータを保存するためにこのサイトを使用しないでください | アプリのデータモデルが確立されている場合、この環境を使用してください。 アプリを開発するときは、この環境を使用してください。 テストデータを入力するときに使用してください。 |
| 製造 | ddb.arup.com (opens new window) | 最後に、DDB 生産サイトがあります。 このサーバーはライブプロジェクトデータをホストし、安全です。 このサイトに作成された機能の更新は、開発サーバーとサンドボックスサーバーでの徹底的なテスト後にのみ実装されます。 | データモデルとアプリのフローが十分にテストされ、確立されている場合、この環境を使用します。 |
# 計画
プロジェクトは、ジョブ番号にリンクされた情報のコレクションです。 DDB の各プロジェクトには独自のページがあります。
# この情報はどのように保存されていますか?
# 資産
資産は、プロジェクト内のサイトやシステムなどの物理的なものです。 これらはすべて、物理的に存在するものであり、それらに割り当てられたパラメーターを持っています。
# 資産階層
資産階層は、資産が編成される方法です。 資産には、親の資産と子の資産を持つことができます。つまり、サイト(親)には 1 つ以上の建物(サイトの子供)が含まれ、各建物には 1 つ以上のシステム(建物の子供)が含まれています。 これらの関係は、DDB で事前に定義されています。
資産階層は、上から下に設定する必要があります。 したがって、ツリー階層の最下部でデータに取り組むことを試みている場合でも、トップレベルのアセットインスタンスを作成する必要があります。 資産ツリーの階層と親と子の関係の詳細については、参照してください ここ 。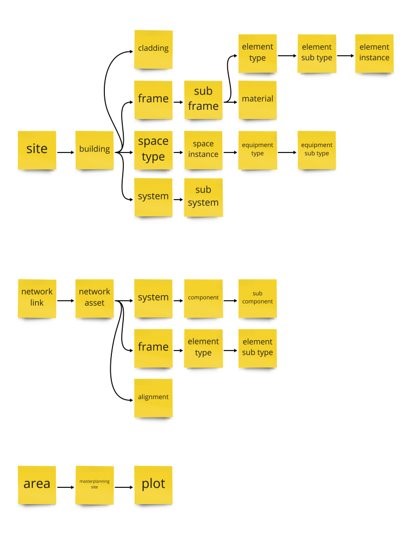
# パラメーター
パラメーターは資産の特性です。 これらは、計算とレポートで通常使用される値です。 各パラメーターにタグを付けて、パラメトリック情報の効果的な組織を可能にすることができます。 パラメーターは、クライアント名、密度、温度、具体化された炭素などです。
タイプ、単位、値など、パラメーターにはいくつかのコンポーネントがあります。 例えば
| パラメーター | 例 |
|---|---|
| パラメータータイプ | 長さ |
| ユニット | m |
| 値 | 7 |
| 親資産 | テストルーム |
# DDB タイプ
DDB データは、の観点から定義されます 種類 と インスタンス 、同じように、Revit データが家族やインスタンスに構造化されています。 これらのタイプは、データに構造を提供し、インスタンス自体にどのデータを含めるべきかを概説します。 たとえば、アセットインスタンスはアセットタイプで定義され、パラメーターインスタンスはパラメータータイプで定義されます。
「Building」は資産タイプであり、「Building A」と呼ばれるプロジェクトの建物は資産インスタンスです。 「温度」はパラメータータイプであり、「構築」の温度はパラメーターインスタンスです。
それについて考えるもう 1 つの方法は、タイプが複数の場所(プロジェクトに複数の建物を持っているなど)に存在できることですが、インスタンスは 1 つの場所にのみ存在し、プロジェクトに必要な特定のデータを含めることができます。
DDB タイプの詳細については、を参照してください データ構造 セクション。
# ID/GUID
GUID(「グローバルに一意の識別子」)は、識別(ID)を表す 128 ビットのテキスト文字列です。 DDB は GUID を使用して、タイプ、インスタンス、およびプロジェクトを識別します。
たとえば、プロジェクトは、ジョブ番号または55c434c8-3817-4cc1-b7ec-f8e25e79ad67などの URL で見つけることができる一意の ID によって識別できます。
# 鬼ごっこ
タグはコンテキスト情報を提供し、よりプロジェクト具体的な方法でパラメーターにラベルを付けることができます。 タグは多くのカテゴリで利用でき、それらを使用する規律、使用されている計算、またはそれらを必要とするレポートに基づいてパラメーターを並べ替えることができます。 タグは、データに関連付けられた貴重なメタデータを提供します。
例としては、熱快適性に関連付けられたすべてのパラメーターにタグを付けることです。
# データ型
DDB 内では、プロジェクトデータはさまざまなデータ型に保存されます。 これらは、各パラメーターが保持できる値のタイプを決定し、データで実行できる操作を定義します。
DDB で使用されるデータ型は次のとおりです。
- 弦 - 文字、数字、シンボルなどの文字の組み合わせ。 これらは多くの場合、名前や単語を保存するために使用されます。 例えば。 "イングランド"
- 整数 - このデータ型は、通常、量の資産に使用される整数の保存に使用されます。 例えば。 12
- 浮く - これは、技術的なパラメーターの大部分を保存するために使用される分数の数値の保存に使用されます。 例えば。 5.24
- ブール - これは、「真」または「偽」値のいずれかであり、通常は何かが必要かどうかをマークするために使用されます。 例えば。 真実
- 日にち - これは特定の日付であり、通常はプロジェクトの開始日や終了日などのものをマークするために使用されます。
# 情報源
DDB 内では、すべての情報のソースが特定されます。 これらのソースには、それらに割り当てられたタイプ、ソース、および参照(該当する場合)があります。 ソースタイプとソースの例には次のものがあります。
- 自動的に入力されます - プロジェクトが DDB に追加されたときに生成される広告情報など、自動的にそれらを埋めるプロセスを持つパラメーターの場合。
- 顧客台帳 - クライアントが必要とする値について。
- 法律 - 統治体が必要とする制限のため。
- 派生価値 - DesignCheck 経由などの計算によって生成された値またはモデルシミュレーションなどの別のプロセスについて。
他のソースタイプには含まれます プロジェクトのドキュメント 、 仮定 、 業界のガイダンス 、 学術雑誌 、 調査 、 また 公式出版物 。
# データ品質

プロジェクトのすべてのパラメーターについて、データのバージョン履歴、情報のソースを確認でき、各エントリの品質保証のレベルを明確に確認できます。
品質保証のレベルは、未回答、回答、チェック、および承認されています。 いつでも、それは拒否される可能性があり、QA プロセスの開始に戻ります。
- 未回答 - これは空のフィールドです。 まだ入力されていないデータはありません。
- 答えた - データが入力されており、これを完全なトレーサビリティで確認できます。
- チェックしました - 以前の入力データは、プロジェクト手順に沿ってチェックされています。
- 承認済み - 情報はプロジェクト手順に沿って承認されています。
- 拒否された - 情報は拒否され、変更のためにマークされています。
# ユーザー許可
DDB は、機密情報へのアクセスを制御するためのユーザー許可を定義しています。 ユーザー許可はロールベースです。つまり、DDB ユーザーは、定義されたロールに基づいてさまざまなレベルのアクセスを割り当てることができます。
5 つの役割があります - 読者 、 編集者 、 チェッカー 、 承認者 、 と 管理者 。
を参照してください ユーザー許可ガイド 詳細については。
← DDB を始めましょう▶️ データ構造 →